
AI Scraping Benchmarks
AI is great at scraping, but how do you keep cost down without losing accuracy?

AI models have the potential to make web scraping 10x easier. Instead of writing complicated code like XPath and CSS selectors, you can scrape a website with plain English. That’s the idea behind FetchFox, a Chrome extension that scrapes any website using AI.
You tell FetchFox what to scrape, and it extracts your data in seconds. It opens up scraping to 100x more people than before.
We launched a few weeks ago, and the initial reception was great. Unfortunately, we quickly got a complaint:

And another:

And we noticed this in the project’s OpenAI account:
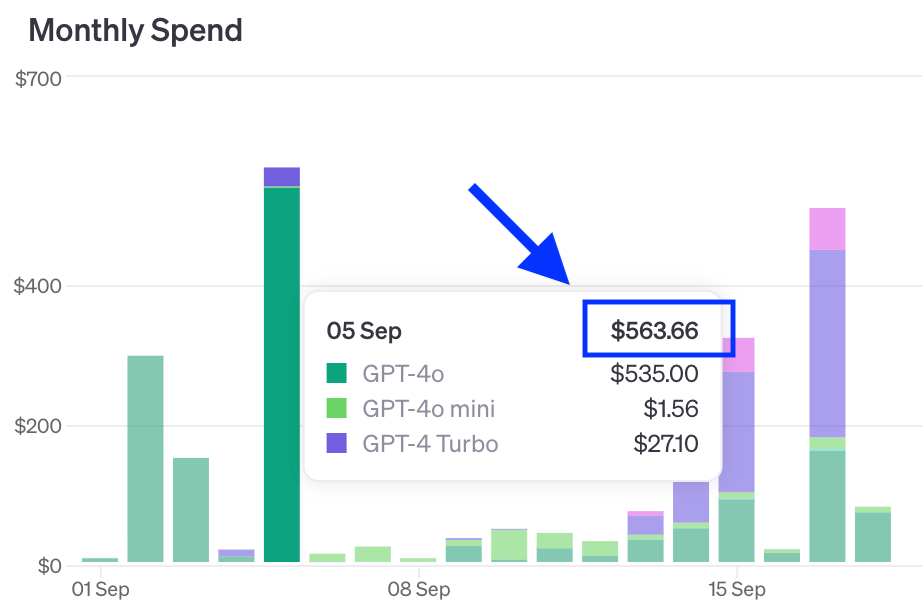
Scraping web pages with AI is very effective, but it can run up costs if you are not careful!
In our case, we were running the GPT-4o model from OpenAI. This is their most advanced model, and also the most expensive. As an emergency fix, we switched over to GPT-4o-mini. An eyeball test showed that it was just as good, just as fast, and 30x cheaper.
Where’s the data on AI scraping?
An eyeball test is ok in a pinch, but how do we know we’re not hurting quality when we switch the model? Or when we switch prompts? Scrapers need to work well in all situations, from popular websites to tiny niches. We need a set of objective benchmarks to compare AI scrapers.
To this end, we’re developing a set of benchmarks for AI scrapers. We are focusing on the following factors, which are the most important for user experience:
Accuracy: Does the scraper provide the correct answers?
Token usage: How many tokens are required?
Cost: How much does each scrape cost?
Runtime: How long did it take to get an answer?
To support the benchmarks, we’re developing and publishing two open source libraries:
First, we’re publishing FoxTrot. This library is the backend of the extension, handling things like model interaction and prompting. It can be integrated into other scraping projects.
Second, we’re publishing an AI scraping benchmark tool. This tool runs different AI scrapers on a set of web pages, and compares their answers to a human’s answers. It scores each AI scraper on the metrics above.
Configuring the best AI scraper
The FoxTrot library makes it easy to configure different AI scrapers. In addition to configuring the service provider and model, you can also change prompts, algorithms, and pre-processing heuristics.
For the first set of benchmarks, we’re going to try the following variables:
AI models: We’ll try some of the most popular private and public AI models:
OpenAI: gpt-4o, gpt-4o-mini
Anthropic: claude-3.5-sonnet, claude-3-haiku
Groq: llama3-8b-8192, llama3-70bb-8192
Ollama: llama3.1:8b, llama3.1:70b, codellama:13b, codellama:70b
Google: gemini-1.5-flash
Our Ollama instance is hosted on Koyeb.
Extractors: An extractor takes the HTML of a page, and gets data out of it. FoxTrot lets you vary the extractor you use, and we’re going to try two:
SinglePromptExtractor: This takes all the fields in your scrape, and sends them to the AI in a single prompt. It requests a JSON answer to all the fields.
IterativePromptExtractor: This sends fields one-by-one to the AI. It uses more tokens, but it’s a simpler task for the AI.
Minimizers: A minimizer does pre-processing on HTML to reduce its size. This reduces token counts, which in turn reduces cost and runtime. However, doing so risks losing information. We’re going to try four:
No minimizer: Send all the HTML and text to the AI, with no changes.
TagRemovingMinimizer: Removes tags that are unlikely to contain useful data: <style>, <script>, and <svg>
TextOnlyMinimizer: Extracts all the text from the page.
ExtractusMinimizer: Uses the extractus library to get the main content of the page.
Scoring
Each combination of AI model, extractor, and minimizer is benchmarked separately against hundreds of scraper fields. This gives us thousands of data points to evaluate. We’re going to rank each combination on accuracy, runtime, and cost, as well as a composite rating. The composite rating formula is:
Rating = Accuracy * Penalty * (Runtime Score + Cost Score)Runtime and cost are scored based on the needs of a production system, and the penalty is applied if either value is too far out of the usable range. For our testing, a runtime under 4 seconds is good, and a cost of under $1 per thousand pages is good. A runtime under 10 seconds is ok, and a cost under $5 per thousand pages is ok. Anything above is considered bad. You can review the exact scoring function in a GitHub gist.
The rating gives us a ranking that accounts for the tradeoff between accuracy and cost.
The test cases
We’ll run tests against a variety of sites like NPM, Wikipedia, Hacker News, Reddit, and more. Each site is scraped for a handful of fields, and all the fields have objective, correct answers. You can check out the entire list of test cases in our benchmark repo.
And the winner is…
Our testing gave a wide range of results, with some AI scrapers giving great, low cost results, and others not so much.
Let's start with the best. Below are the top 10 AI scrapers in our testing, ranked by the composite score.

The clear winner is OpenAI’s GPT-4o-mini model, running on the text only. That model gives the best tradeoff between accuracy, cost, and runtime.
The next three slots are taken by variations on using GPT-4o-mini: keeping HTML improves a little on accuracy, but triples the cost. The extractus library cuts cost by half compared to the text only approach. However, it is overly aggressive and cuts accuracy by half as well.
The llama3-8b offerings from Groq are interesting. They are by far the cheapest options, costing 3x less than GPT-4o-mini on a per token basis. Unfortunately, their accuracy never tops 62%. This is due to their limited context window, which is capped at 8192 tokens.
Finally, although Groq bill themselves as “Fast AI Inference,” and their demos are impressive, reality is different: their current production system is unreliable. In my testing, it was sometimes very fast, sometimes very slow, and sometimes returned an error.
Who’s the most accurate?
Putting aside concerns like cost and runtime, which are very important for a production system, it's interesting to see which are the most accurate models. Below are the top 10:

OpenAI is the winner again, with Anthropic’s 3.5 model performing well also. Unfortunately, Anthropic is too costly and slow to use in production. Additionally, their rate limits on small accounts are very aggressive, and unusable for scraping.
Interestingly, the iterative prompts do not perform very well. These prompts ask one question at a time. For example, if you are scraping a page about Pokemon, the iterative prompt sends one query for the Pokemon’s name, another query for the Pokemon’s number, and so on, until all fields are collected. The single prompt asks all the questions at once.
Perhaps having multiple answers helps the AI think. Regardless, there doesn’t seem to be any benefit to using the iterative prompt approach, at least for the top models. Some of the poor performing models got a bump from the iterative approach.
Digging into the details
In addition to the aggregate data, FoxTrot’s benchmarks also let you get the details of each scraper’s performance. You can see a scorecard, like the one below for OpenAI’s GPT-4o-mini model.

The green check marks indicate all correct answers. Yellow with a negative number shows how many it got wrong.
To get even more detail, you can inspect each test case individually. For example, below are the results of an attempt to scrape a page from Genius.

The AI made a mistake on formatting. It got the right data (“2.8M”), but it did not expand the number into the format we asked.
A quick glance over the test cases shows some patterns:
Formatting errors are common. The AI will often ignore requests to expand numbers, convert units, and remove commas.
The AI will sometimes give a “close enough” number. For example, while scraping Pokemon, it will often fudge Pokedex numbers by a little bit.
Hallucination happens with scraping also. Sometimes, the AI just makes up an answer!
An egregious example is below. When asked to scrape a page about Guzzlord, codellama13b just assumed all Pokemon are either Pikachu or Eevee. Oops.
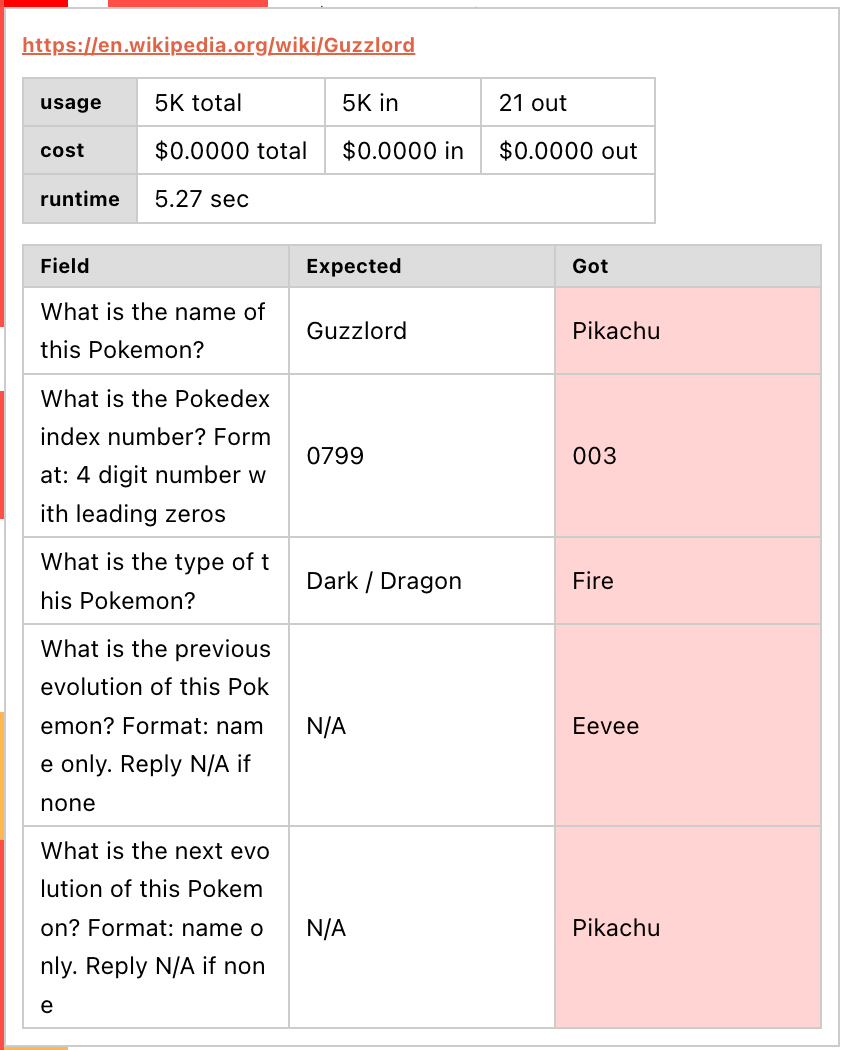
Despite these mistakes, the AI scraping models are impressive, especially the newest models.
AI is bad at writing XPath
We tried one approach that failed badly: asking the AI to write XPath selectors. This seemed like a promising approach: you could ask the AI to write an XPath selector for each field, and use that same code on dozens or hundreds of pages.
Unfortunately, AI is very bad at writing XPath. It doesn’t have a good intuition for which selectors are reliable, and which are brittle. It will often use garbage selectors like x11i5rnm that carry no semantic meaning and aren’t usable across different pages. This is despite aggressive prompting to find only stable selectors, and to give up if it can’t find a good answer.
Next steps
Our next goal on the FoxTrot library is going to be bringing down the cost and runtime on AI scraping. We think there can be improvements here using heuristics and cheaper machine learning methods in pre-processing. Some ideas we’ll try include:
Removing long class name attributes. Modern web frameworks obfuscate CSS classnames, and removing them is unlikely to lose information.
Non-AI machine learning to slim down code. Modern pages have many, many tokens that are irrelevant to the scrape fields. Its expensive to run them all through AI. What if a cheaper ML algorithm can remove the stuff that’s obviously useless?
If you have ideas on how to improve AI scraping, join our Discord and chat with the devs.
Try it yourself
If you’re interested in digging through the details, check our website: we’ve published our AI scraper benchmarks.
Additionally, you can find our benchmarking repo as well as the core scraping library repo on GitHub.